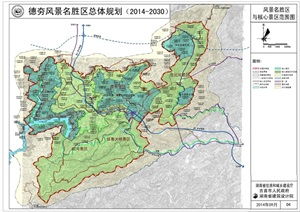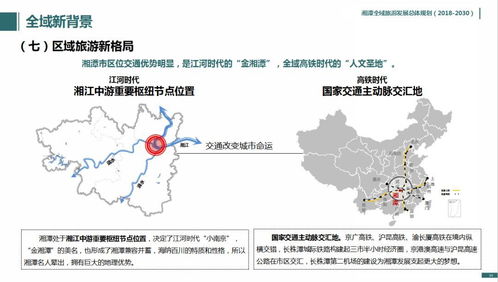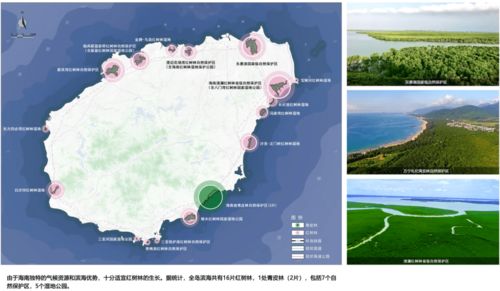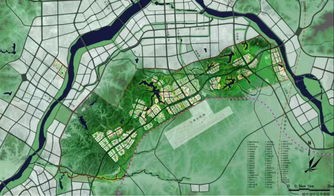
在國家大力推動健康產業與旅游業融合發展的背景下,上饒國際醫療旅游先行區應運而生,致力于打造一個以高端醫療為核心、生態康養為特色、文化旅游為延伸的綜合性國際健康目的地。其旅游項目規劃,充分依托上饒得天獨厚的自然生態與人文底蘊,構建起一個多層次、全周期的健康旅游體驗體系。
一、 核心規劃理念:醫、養、游深度融合
先行區的規劃核心在于打破傳統醫療與旅游的界限,并非簡單疊加。它以國際前沿的醫療服務(如精準體檢、特色診療、康復療養)為吸引核,以武夷山脈、三清山等區域的優越生態環境為承載基底,同時深度融入上饒的稻作、茶、道教等文化元素,形成“醫療驅動、康養主導、旅游賦能”的創新發展模式。目標是讓游客在獲得健康管理的享受身心放松的文化與自然之旅。
二、 主體功能區與重點項目規劃
規劃布局通常涵蓋以下幾大功能板塊,具體項目可能包括:
- 國際高端醫療核心區:
- 項目示例:國際醫院/診療中心群。引進國內外頂尖醫療團隊和技術,提供腫瘤防治、心腦血管疾病管理、生殖健康、醫學美容等特色專科服務。配套多語種服務和國際保險直付體系,滿足境內外游客需求。
- 旅游融合點:提供“醫療檢查+術后康復+休閑度假”一站式套餐,將治療周期轉化為舒適的旅居體驗。
- 生態康養度假區:
- 項目示例:森林康養基地、溫泉療愈中心、中醫藥健康村落。利用森林、溫泉、富硒資源及本地豐富的中草藥資源,開發森林浴、溫泉理療、中醫針灸、膳食調理等系列康養產品。
- 旅游融合點:設計主題康養線路,如“七日中醫調理之旅”、“富硒膳食養生之旅”,結合山水觀光、農耕體驗。
- 活力健康管理區:
- 項目示例:國際健康管理中心、運動康復公園、智慧健康社區。提供深度健康風險評估、個性化健康計劃制定、運動指導及慢病管理服務。
- 旅游融合點:舉辦國際健康馬拉松、山地自行車賽、太極/瑜伽養生營等賽事與活動,吸引運動休閑游客。
- 文化旅游體驗區:
- 項目示例:道教養生文化園、茶文化康養莊園、非遺工坊體驗區。挖掘道教養生智慧、茶道精神以及本地非遺技藝(如歙硯、婺源三雕),開發文化靜修、茶療、手工藝創作等體驗項目。
- 旅游融合點:將文化體驗作為醫療旅游的情感與精神補充,設計“問道養心”、“茶香靜修”等文化療愈課程。
- 綜合服務與支持區:
- 項目示例:醫療旅游服務中心、人才培訓基地、研發孵化平臺。提供咨詢、預約、翻譯、交通等一站式服務,并保障區域的持續創新與人才供應。
三、 特色與創新亮點
“定制化”健康旅程:根據游客的健康狀況與需求,靈活組合醫療項目、康養活動和旅游景點,形成獨一無二的個性化行程。
“全域化”資源聯動:規劃不僅局限于先行區范圍內,更通過交通線路和合作機制,聯動三清山、婺源、龜峰等上饒全域頂級旅游資源,形成“一點接入、全域服務”的格局。
“智慧化”平臺支撐:預計將構建統一的醫療旅游數字平臺,整合預約、健康檔案管理、遠程咨詢、行程導航等功能,提升體驗的便捷性與科技感。
“國際化”標準服務:從設施建設到服務流程,均對標國際標準,營造無障礙的國際化環境,旨在吸引“一帶一路”沿線國家及全球華人華僑客群。
四、 展望與意義
上饒國際醫療旅游先行區的旅游項目規劃,描繪了一幅“在山水間療愈,在文化中新生”的動人圖景。它不僅有望成為長三角地區乃至全國醫療旅游的新高地,推動上饒產業轉型升級,更探索了一種以人的全面健康為中心的區域發展新模式。隨著項目的逐步落地,這里將成為國內外尋求高品質健康生活人士的理想目的地,真正實現“醫在饒城,養在山水,游在畫中”的美好愿景。